
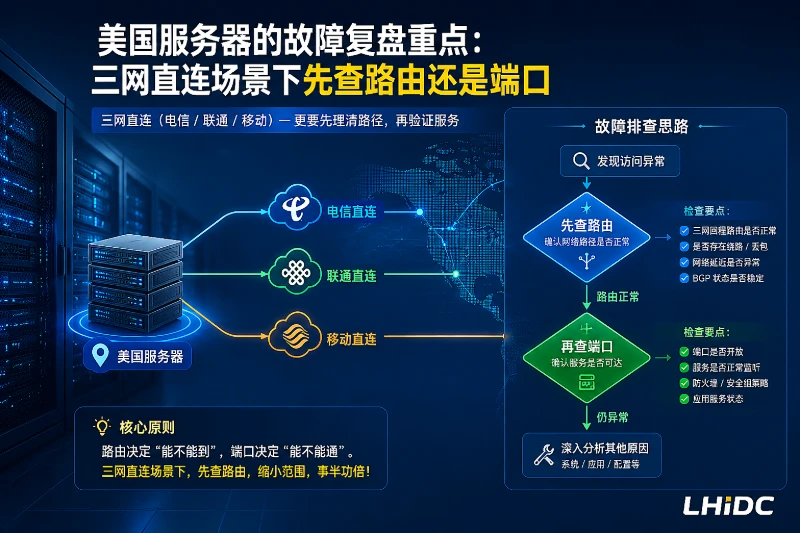
美国服务器的故障复盘重点:三网直连场景下先查路由还是端口
美国服务器访问不稳时,先按症状范围、路由、端口和应用层的顺序排查,区分网络链路问题与业务并发问题。文章面向后端开发工程师和企业IT部门,重点说明复盘应保存的路由、端口、日志与变更证据。
先把现象拆开:是整网不通,还是部分请求不稳
美国服务器在交付验收后如果出现“能打开,但偶尔慢”“某些用户能访问,某些用户超时”“同一个域名下只有一个接口报错”这类现象,先不要急着把责任压到线路或者应用上。三网直连场景里,电信、联通、移动的路径本来就可能不同,单次 ping 通、单次 traceroute 抖一下,都不足以直接判定线路失效。
更稳妥的做法是先缩小故障范围:看是所有网络都受影响,还是只影响某一运营商;看是所有端口都异常,还是只影响某个业务端口;看是连接阶段失败,还是已经连上后响应变慢。范围先拆开,后面的路由、端口和应用层判断才有意义。
排查顺序:先路由,再端口,最后应用层
默认顺序建议是:症状范围 → 路由 → 端口连通 → 应用层日志与资源。 这个顺序适合大多数美国服务器访问不稳的场景,因为它能把“网络没到服务器”与“请求到了但服务没处理好”区分开。
| 层级 | 重点看什么 | 典型含义 |
|---|---|---|
| 路由层 | traceroute、mtr、路径变化、丢包、绕路 |
更像线路或中间链路问题 |
| 端口层 | TCP 握手、端口监听、ACL/防火墙 | 更像服务未监听、端口被拦、连接未建立 |
| 应用层 | 访问日志、错误日志、队列、CPU、内存、连接池 | 更像并发、依赖、程序处理慢 |
有一个边界要特别注意:单次抖动不能直接判定线路失效。如果只是一次 mtr 某一跳丢包,后续探测恢复正常,先按临时抖动处理,继续采样,不要过早下结论。
逐项检查:路由先看“路有没有变”
路由检查要看可重复性
三网直连场景下,路由问题最怕只看一条样本。验收或复盘时,最好分别保存来自电信、联通、移动的路径结果,再看是否出现持续性的路径变化、异常绕行或持续丢包。
Linux 环境可先用这些命令:
mtr -rwzc 20 your.domain.com
traceroute your.domain.com
ping -c 20 your.domain.com
如果是 Windows 环境,可以用 tracert 和 Test-NetConnection,但要先确认目标是 TCP 端口还是 ICMP 探测。很多节点会限制 ICMP,所以“ping 不通”不等于“业务不通”。
路由层更适合判断这些情况:
- 同一时段内,多个来源都走到同一条异常路径
- 某一运营商持续表现异常,而另外两网正常
- 延迟波动和丢包是重复出现的,不是偶发一次
如果只有一次探测异常,后续恢复正常,先保留记录,不要直接写进“线路故障”结论里。
端口检查要看握手是否真正建立
路由看起来正常后,再查端口。因为“路到了”不代表“服务能接”。对于 Web、API、下载、数据库代理等业务,端口是否监听、是否被防火墙或安全组拦截,是必须单独确认的。
nc -vz -w 3 your.domain.com 443
curl -I --max-time 5 https://your.domain.com/health
ss -lntp | grep ':443'
如果你部署的是 Nginx、Apache、Node.js、Java 服务,先确认服务进程是否真的在监听目标端口,再看防火墙和安全策略。常见判断可以这样分:
connect refused:更像端口没监听,或服务已停connect timeout:可能是网络链路问题,也可能是防火墙丢包- 能连上但返回慢:继续往应用层查,不要停在端口层
这里有个经验判断:路由正常、端口通,但业务页面或接口仍不稳,通常就不是“线路断了”,而是程序处理、依赖组件或并发能力出了问题。
应用层怎么分清网络故障和并发问题
当端口连通正常,接下来就要看应用层。很多后端故障复盘之所以卡住,是因为把“请求慢”直接等同于“网络差”,其实两者表现并不一样。
更像网络故障的特征
- 不同客户端都访问失败,且失败点集中在连接建立阶段
- 路由探测出现持续异常,且可重复
- 应用日志里常常看不到完整请求进入记录
- 同一业务端口在不同运营商上表现差异明显
更像并发或业务处理问题的特征
- 路由稳定,端口能连上,但响应时间明显变长
- 错误集中在高峰期,低峰期明显缓解
- 日志里能看到请求已进入服务,但出现超时、队列满、线程耗尽、连接池不足等现象
- CPU、内存、负载、磁盘 I/O 或数据库等待时间同时抬高
Linux 上常见的辅助检查可以包括:
top
vmstat 1 5
iostat -x 1 5
journalctl -u your-service --since "10 minutes ago"
grep -E "timeout|error|upstream" /var/log/nginx/error.log
如果是 Java、PHP、Go、Node.js 等不同技术栈,日志路径会不一样,但判断逻辑相同:先确认请求有没有进入应用,再确认卡在入口、队列、依赖,还是业务代码本身。
处理时别把“修复”做成二次扰动
复盘定位完成后,处理动作要和根因对应。
- 路由异常:保留时间点、来源运营商、目标 IP、路径结果,交给线路侧或机房侧进一步核对
- 端口异常:确认服务是否启动、监听地址是否正确、配置是否被改动,必要时在变更前先备份配置
- 应用并发问题:检查连接池、线程池、队列长度、慢请求和依赖超时,先做限流、扩容或参数调整,再评估长期优化
如果你的业务本身是外贸官网、企业站或 API 服务,三网直连的美国服务器在验收时最好把“正常路由截图、端口探测结果、健康检查接口返回值”一起留档。后面再出问题,就能直接对比,而不是从零猜测。
对于视频点播、文件下载、跨境业务这类大流量场景,带宽和硬件配置固然重要,但它们不能替代排障顺序。带宽够不够,是容量问题;路由稳不稳,是路径问题;应用抗不抗压,是处理问题。三者不要混在一起看。
复盘时要保存哪些证据
故障复盘能不能落地,关键不在“描述得像不像”,而在证据是否完整。建议至少保留下面这些内容:
- 故障开始和恢复的准确时间,注明时区
- 受影响的来源网络:电信、联通、移动,尽量分别留样
- 路由探测结果:
mtr、traceroute、必要时的重复采样 - 端口连通结果:
nc、curl、Test-NetConnection输出 - 应用访问日志和错误日志
- 服务进程、监听端口、CPU、内存、负载、I/O 快照
- 变更记录:发布、重启、配置修改、防火墙调整
- 客户端侧的报错截图或原始返回码
其中最重要的一点是:不要只保存一次成功或一次失败的结果。复盘要看的是趋势和重复性,不是单帧画面。单次抖动、单次超时、单次丢包,都只能算现象,不能直接写成根因。
修复后还要继续观察什么
故障修完,不代表可以立刻翻篇。三网直连场景下,建议继续观察一段时间,重点盯这三项:
- 同一来源、同一端口的重复探测结果是否稳定
- 应用日志里是否还出现超时、重试、连接耗尽
- 不同运营商的路由是否回到稳定状态,还是只恢复了其中一条链路
如果后续还会承载更高并发,最好把这次复盘得到的“正常路由基线”和“端口健康基线”固定下来。以后再遇到美国服务器访问不稳,就能先按证据判断是路由、端口还是应用层,而不是靠经验猜。