
香港服务器API请求超时,如何区分跨境链路问题和应用并发不足
当香港服务器上的API出现超时告警时,应先按客户端区域、链路延迟、丢包和应用并发逐层判断,避免把所有问题都归因于网络。文章结合日志与监控证据,帮助API运维人员区分跨境链路波动与服务端排队拥塞。
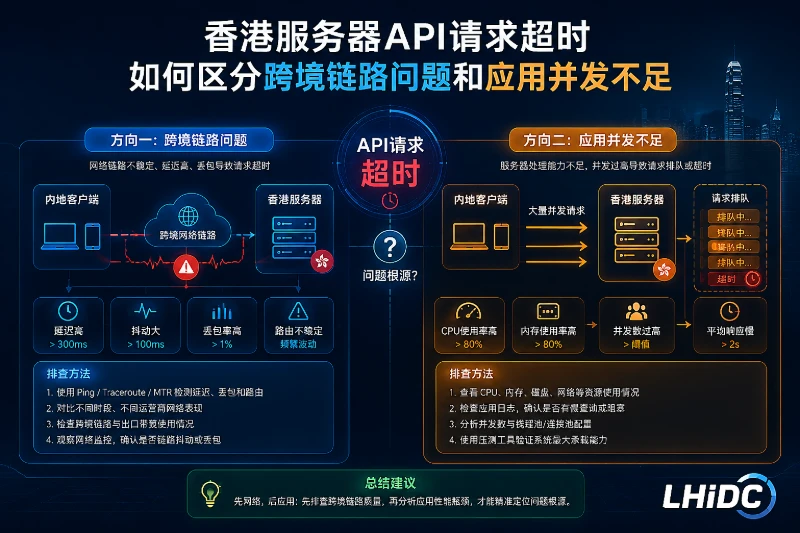
收到香港服务器上的 API 请求超时告警时,先别急着把原因直接归到“带宽不够”或“代码有问题”。先看超时是不是集中在某些客户端区域,再看链路耗时是否异常;如果不同区域表现一致,而连接池、线程池和排队时间同时抬高,才更像应用并发不足。
排查顺序最好固定下来:先排除外部因素,重点看客户端区域与超时分布;再做链路延迟和丢包检查,确认是不是跨境链路波动;接着进入服务端,检查连接池、并发水位和下游依赖;最后把日志与监控放到同一时间线上对齐,避免只看单点数据下结论。
先看客户端区域与超时分布
API 超时不是先看“总量”,而是先看“分布”。
如果超时主要来自内地某几个省份、某些运营商,或者只在从特定区域访问香港服务器时出现,跨境链路的优先级就会上升。 如果香港本地、内地、海外客户端在同一时间段都出现类似超时,且分布较均匀,网络链路的解释力就会下降,应该更快转向服务端并发和下游依赖。
建议先把这几个维度拆出来:
- 客户端区域:省份、国家/地区、城市
- 运营商:电信、联通、移动,或海外 ISP
- 接口维度:哪些 API 慢,哪些正常
- 时间维度:是否集中在固定时段、峰值时段或发布后
- 请求结果:超时、5xx、客户端主动断开、重试成功
如果接入层前面还有 CDN、WAF、负载均衡或网关,不要把边缘节点的超时直接算到源站。先分别看边缘日志和源站日志,才能知道问题落在哪一段。
检查跨境链路的延迟和丢包
链路问题通常不是“完全不通”,而是连接建立慢、抖动大、偶发丢包,最后体现在 API 等待时间上。
以下以 Linux 为例,命令需按你的实际域名、端口和环境调整;如果是 Windows 服务器,可以用性能监视器、资源监视器和事件查看器做同样的观察。
# 看基本连通性
ping -c 20 api.example.com
# 看路径、抖动和丢包
mtr -rwzc 20 api.example.com
# 看请求阶段耗时,区分 DNS、连接、TLS 和首包
curl -o /dev/null -s -w 'dns:%{time_namelookup} connect:%{time_connect} tls:%{time_appconnect} ttfb:%{time_starttransfer} total:%{time_total}\n' \
--connect-timeout 5 --max-time 15 https://api.example.com/health
# 看服务端当前连接状态,把 443 换成实际端口
ss -tan state established '( sport = :443 )'
ss -s
看这些结果时,重点不是单个数值,而是趋势和组合:
time_connect、time_appconnect明显抬高:更偏向链路、握手或路由问题time_starttransfer高,但连接建立很快:更偏向服务端处理慢mtr显示中间链路抖动大,最终也有丢包:需要重点关注跨境路径ping看起来正常,但curl连接阶段很慢:不要只凭 ping 判断链路- 从客户端侧慢、从香港服务器回测客户端也慢:更像双向路径问题
- 只有从某些区域慢,其他区域正常:更像局部跨境链路,而不是整体服务退化
如果你已经确认是从内地访问香港服务器时更慢,且慢点集中在连接建立或 TLS 阶段,那就先别急着扩容应用实例。很多时候,先改路径和接入方式,比加机器更有效。
再看服务端:连接池、并发和排队水位
如果链路检查没有明显异常,就进入服务端。这里要看的是“服务有没有接得住请求”,而不是只看 CPU 是否满。
重点关注这几类指标:
- 应用连接池是否接近上限,等待获取连接的请求是否增多
- 线程池或 worker 是否长期繁忙,队列是否持续堆积
- 网关或反向代理的
upstream_response_time是否拉长 - 是否出现大量 499、504、超时重试和请求取消
- 数据库、缓存、第三方接口是否成为慢依赖
- CPU、内存、磁盘 I/O 是否在峰值时段同步升高
有些超时看起来像“网络慢”,实际上是请求在服务端排队太久。 例如连接池已满,后续请求只能等待;线程池占满后,新的 API 只能排队;数据库慢查询堆积后,应用层再快也会被拖慢。此时就算链路完全正常,客户端也会看到超时。
一个常见误判是:看到响应慢,就直接增加应用线程数。 如果真正瓶颈在数据库连接池、下游服务或磁盘 I/O,线程加多只会让排队更严重。先确认“哪里在等”,再决定是否扩并发。
用日志和监控把证据串起来
排障时,最有价值的是同一时间窗里的多类证据,而不是一条超时日志。
建议整理成同一份时间线:
- 客户端区域分布
- 接口访问日志
- 网关或反向代理日志
- 应用错误日志
- 系统资源监控
- 链路探测结果
- 最近的发布、扩容、配置变更
下面这张表可以作为快速分叉的参考:
| 现象 | 更像链路问题 | 更像并发不足 |
|---|---|---|
| 超时集中在少数区域或运营商 | 是 | 否 |
connect/appconnect 时间高 |
是 | 否 |
ttfb 高但连接建立正常 |
可能有影响 | 是 |
| 所有区域都在峰值时段同时超时 | 否 | 是 |
| 连接池等待明显增加 | 否 | 是 |
| 路径抖动、丢包、握手重试增多 | 是 | 不一定 |
如果日志和监控都指向同一时间点,就要看是否有发布、证书更新、网关改动、连接池参数变更,或者下游服务抖动。很多“突然超时”其实是变更后才暴露出来的。
分支处理:确认原因后怎么改
更像跨境链路问题时
先处理接入路径和客户端体验,再考虑服务端扩容。
可以优先做这些事:
- 对比不同区域的访问路径,确认问题是否只出现在跨境链路上
- 检查 DNS 解析、路由切换和回源路径是否稳定
- 增加重试要谨慎,必须配合幂等设计和退避策略
- 对关键接口设置更清晰的超时边界,避免长时间挂起
- 如果业务主要面向内地访问香港节点,线路稳定性要放进选型里
这类场景下,香港服务器的线路和接入方式会直接影响体验。比如已知业务需要承接跨境访问时,选择带有 CN2+BGP 组合线路的香港服务器,通常更适合把“路径不稳”这类风险纳入部署方案;但是否真正需要,还是要以你当前探测到的区域分布和链路结果为准,不能只凭感觉判断。
更像应用并发不足时
先处理“接得住多少请求”,再处理“单个请求有多快”。
常见动作包括:
- 检查并调整连接池,但不要超过数据库和下游能力
- 优化线程池/worker 的队列和上限,避免无界堆积
- 缓存热点接口,减少重复下游调用
- 将慢任务异步化,避免阻塞主请求链路
- 给高峰期设置限流和降级策略,保护核心接口
- 复核实例规格是否匹配峰值并发和内存占用
如果最终确认是并发和资源瓶颈,再回看香港服务器规格会更有意义。数据库和多业务部署场景,往往更看重大内存;高并发网站和企业应用,通常更需要更稳的连接承载空间。现有产品里,香港至强大内存服务器更适合数据库、多业务部署和高并发网站;香港 AMD 高性能服务器更适合跨境电商、SaaS 平台、游戏后端这类计算和 I/O 压力更活跃的业务。具体选哪种,还是要看你是卡在连接池、内存,还是下游处理能力。
修复后怎么验证
改完以后,不要只看“告警没了”,要用同一组条件复测。
建议按这个顺序验证:
- 选同一批客户端区域,重新发起请求
- 选同一接口、同一参数、同一时间窗复测
- 对比修复前后的
connect、ttfb、total和超时率 - 观察连接池等待、队列长度和 5xx 是否回落
- 连续观察一个完整业务峰值周期,确认没有回弹
如果只恢复了某一个区域,而其他区域仍然慢,继续回到链路侧;如果链路指标正常,但首包和排队时间还在抬升,就继续往应用并发和下游依赖方向查。这样收口,才不容易把网络问题和服务端瓶颈混在一起。