
DDoS流量清洗后ping异常,怎样判断是策略拦截还是链路故障
面向运维工程师,说明清洗启用后ping不稳定时的排查顺序:先确认ICMP策略限制,再对比业务端口与日志,结合最小放行、审计和回滚验证区分策略拦截与真实链路故障。
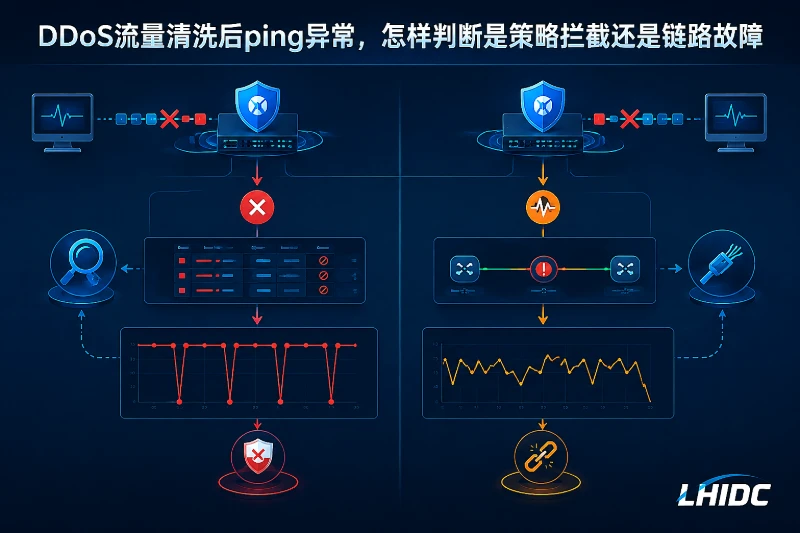
清洗启用后先别急着判定“网络坏了”
攻击一来,DDoS流量清洗一接入,监控里的 ping 开始抖动,甚至直接超时,这是很常见的现场现象。但ping异常本身不能直接等于链路故障。在多数情况下,先要怀疑的是:清洗策略、边界ACL、主机防火墙,或者上游设备对 ICMP 做了限速、丢弃或优先级降低。
判断顺序建议固定下来:先确认 ICMP 是否被安全策略限制,再对比业务端口访问结果,最后才把重点转向链路故障。这个结论成立的前提是:你使用的是同一时间段、同一探测源、同一目标地址做对比。否则很容易把源地址差异、运营商路径差异误判成网络故障。
现有暴露:哪些现象更像策略拦截,哪些更像链路故障
先把故障现象分层,不要只盯着一个 ping 图表。
| 现象 | 更像策略拦截 | 更像链路故障 | 说明 |
|---|---|---|---|
| ping 全部超时,但 80/443 正常可访问 | 是 | 否 | 很多清洗策略会直接限制 ICMP,不影响业务端口 |
| ping 间歇性丢包,但网页、API、SSH 握手正常 | 是 | 可能性较低 | ICMP 被限速时最常见 |
| ping 和 443 同时超时,TCP 握手也失败 | 否 | 是 | 更像链路、路由、上游转发异常 |
| 只有某个源地址 ping 不通,其他探测点正常 | 是 | 可能性较低 | 可能命中地域、信誉、ACL、黑白名单策略 |
| 清洗策略刚变更后立刻出现异常 | 是 | 需要排后 | 先查变更,再查链路 |
| 小包 ping 正常,大包或上传请求异常 | 否 | 是 | 可能是 MTU/PMTU 或链路中间设备处理异常 |
一个实用判断是:如果业务端口可达、应用日志正常、客户端可以完成 TCP/HTTPS 请求,而只有 ping 失败,那么优先查策略拦截,不要先开工查全网链路。
反过来,如果 ping、curl、nc、Test-NetConnection 都一起异常,才值得把重点放到链路、路由回程、运营商路径或 MTU 上。
防护动作:先保业务,不把关闭防护当默认修复方案
清洗后的首要目标不是“让 ping 绿起来”,而是保证业务端口连续可用。因此处置顺序要稳:
- 先冻结当前变更,记录策略调整时间点
- 保留业务必需端口的最小放行
- 保留清洗平台、边界防火墙、主机防火墙的审计日志
- 如果监控必须依赖 ICMP,只给监控源做限速放行,不要全量放开
- 不把“关闭防护”作为默认修复动作,除非已经有充分证据证明策略误杀且有临时补偿措施
这里有个常见误区: 很多监控系统把 ping 失败直接标记为主机不可达,但对启用了 DDoS流量清洗 的业务来说,这个结论并不完整。 更可靠的做法是同时监控:
- ICMP 连通性
- TCP 端口连通性
- HTTP/HTTPS 应用探测
- 安全设备命中日志
- 服务端实际访问日志
配置核对:先确认 ICMP 是否被安全策略限制
从四个位置检查 ICMP
建议按下面四层去看,避免漏查:
- 清洗策略本身
- 是否对 ICMP 做了丢弃、限速、清洗优先级降低
- 是否启用了异常协议包过滤
- 是否存在源地址、地域、信誉库限制
- 边界防火墙或ACL
- 是否放行业务端口但拒绝 ICMP
- 是否只允许特定监控源 ping
- 主机防火墙
- Linux 的
nftables、iptables、firewalld - Windows 防火墙入站 ICMP 规则
- Linux 的
- 主机系统参数
- 是否关闭了 ICMP 回应
- 是否仅对部分协议族响应,例如 IPv4 正常、IPv6 异常
Linux 上先做只读检查
先不要改规则,先看现状。以下命令以常见 Linux 环境为例,执行前请确认系统实际使用的是 nftables、iptables 还是 firewalld。
sysctl net.ipv4.icmp_echo_ignore_all
sysctl net.ipv4.icmp_echo_ignore_broadcasts
sudo nft list ruleset
sudo iptables -S
sudo firewall-cmd --list-all
如果系统参数里 net.ipv4.icmp_echo_ignore_all = 1,说明主机本身就不会回应 ping。
再抓包确认数据包到底有没有到主机:
sudo tcpdump -ni any 'icmp or tcp port 80 or tcp port 443'
抓包结果的判断很关键:
- 能看到 echo-request 到达,但没有 echo-reply 发出 多半是主机策略或系统参数问题
- 看不到 ICMP,但能看到 443 的 SYN/ACK 正常往返 多半是上游策略只限制了 ICMP
- ICMP 和业务 SYN 都看不到 重点转向上游转发、路由或更前面的安全策略
- 主机已经回包,但外部仍显示超时 可能是回程路径、上游过滤或链路不对称问题
Windows 环境重点看防火墙规则
如果目标是 Windows 服务器,优先检查是否启用了 ICMP 回显相关规则,并使用端口探测做对比:
Test-NetConnection -ComputerName <目标IP> -Port 443
若 443 连通但 ping 失败,仍然更像策略限制而不是链路中断。
用业务端口对比,别让 ping 一票否决业务状态
这是区分 策略拦截 和 链路故障 最有效的一步。 请从同一个外部探测点,对同一目标同时做 ICMP 和业务端口测试。
常用对比方法
HTTP/HTTPS 业务可以先这样测:
curl -I --connect-timeout 3 https://<域名或IP>
nc -vz <目标IP> 443
如果是 Linux,可进一步用 TCP 模式的路径探测和 ICMP 模式对比:
mtr --report --tcp --port 443 <目标IP>
mtr --report --icmp <目标IP>
判断逻辑如下:
- ICMP 丢包高,但 TCP 到最终目标稳定
- 不要立刻判定链路坏
- 很多中间设备会降级处理 ICMP
- 更像策略拦截或 ICMP 优先级低
- ICMP 和 TCP 到最终目标都一起抖动
- 更像真实链路问题
- 可能涉及路由收敛、清洗回注路径、运营商转发、回程异常
- ping 不通,但
curl可返回 200/301/401,应用日志也有请求- 基本可以先把“服务器宕机”排除
- 先查安全策略
一个容易误判的边界:MTU 问题
有时 ping 小包能通,但 HTTPS 上传、长连接或大响应异常,这不一定是清洗策略,也不一定是业务程序问题,可能是 PMTU 相关 ICMP 被阻断。
在 Linux 上可以做非分片探测:
ping -M do -s 1472 <目标IP>
如果大包明显异常,而业务也表现为上传卡顿、TLS 建连后数据传输失败,就要检查:
- 路径 MTU 是否变化
- 是否拦截了
fragmentation-needed/packet-too-big - 清洗回注路径是否改变了实际链路
回滚时只回滚最近变更,不整套关闭防护
如果你已经基本确认问题出在策略,不建议一步退回“全关防护”。更稳妥的做法是回滚单一变量。
推荐顺序:
- 先备份当前规则或记录当前策略版本
- 只回滚最近新增的 ICMP 限速、黑名单、ACL 条目
- 保留业务端口防护不动
- 每回滚一项,就用同一组探测再次验证
- 记录恢复前后差异,避免误把短时网络波动当成修复结果
如果本地是 nftables,修改前先导出规则:
sudo nft list ruleset > nft-backup-$(date +%F-%H%M%S).conf
如果需要保留最小放行,思路应是:
- 业务端口按需放行
- ICMP 不全开,只放必要类型或只对白名单监控源开放
- 拒绝规则保留日志,但要控制日志量,避免再次放大压力
一个偏安全的最小放行思路如下,示例仅用于核对方向,应用前请先适配现网规则:
table inet filter {
chain input {
type filter hook input priority 0;
ct state established,related accept
tcp dport { 80, 443 } accept
ip protocol icmp icmp type echo-request limit rate 10/second burst 20 packets accept
ip protocol icmp icmp type { destination-unreachable, time-exceeded, parameter-problem } accept
counter log prefix "drop_input " level info drop
}
}
如果是 IPv6,不能简单照搬 IPv4 处理方式。IPv6 对 ICMPv6 依赖更强,相关必要报文不应一刀切阻断。
复查时重点看“最小放行”和“审计是否够用”
当你把策略调到业务恢复、监控可用之后,还要再做一次复查。重点不是把规则越放越宽,而是确认最小放行是否满足监控和业务。
建议保留以下两类配置:
最小放行建议
- 业务必要端口继续放行
- ICMP 仅按用途开放
- 给监控源开放
echo-request - 保留必要的不可达、超时、参数问题报文
- 给监控源开放
- 不因一次排障把所有协议都改成全放行
审计建议
至少应能看到这些信息:
- 命中的规则编号或策略名称
- 源 IP、目的 IP、协议、端口
- 命中时间
- 动作是丢弃、限速还是挑战
- 同时间段业务访问是否正常
如果日志量过大,建议做采样或聚合,不要让审计本身成为新的负担。
加固后怎么验证才算真的修好
修复后不要只看一次 ping。建议连续做三类验证:
- ICMP 验证
- 确认监控源是否恢复可见
- 确认是否仍有异常高丢包
- 业务端口验证
curl、nc、Test-NetConnection持续正常- 应用日志中请求持续进入
- 没有明显握手超时或重传激增
- 安全与链路联合观察
- 清洗日志是否仍在命中 ICMP 规则
- 路径探测在 TCP 模式下是否稳定
- 网卡错误、系统连接数、应用超时是否同步回落
如果最终表现是:ping 仍然受限,但业务端口稳定、应用正常、日志可解释,这通常就是一个可接受的安全优化状态。 真正需要继续追链路的,是那些ICMP 与业务端口同时异常、抓包也看不到正常业务往返的情况。此时再把抓包、路径探测、变更时间线一起提交给网络侧处理,效率会高得多。