
直播服务器端口够大但仍然卡顿,如何排查共享带宽、出口拥塞和回源链路
面向技术运维人员,说明直播服务器端口看似充足但仍卡顿时的排查方法,重点区分端口速率、保障带宽与实际吞吐,并分析共享带宽、出口拥塞和CDN回源链路对观看体验的影响。
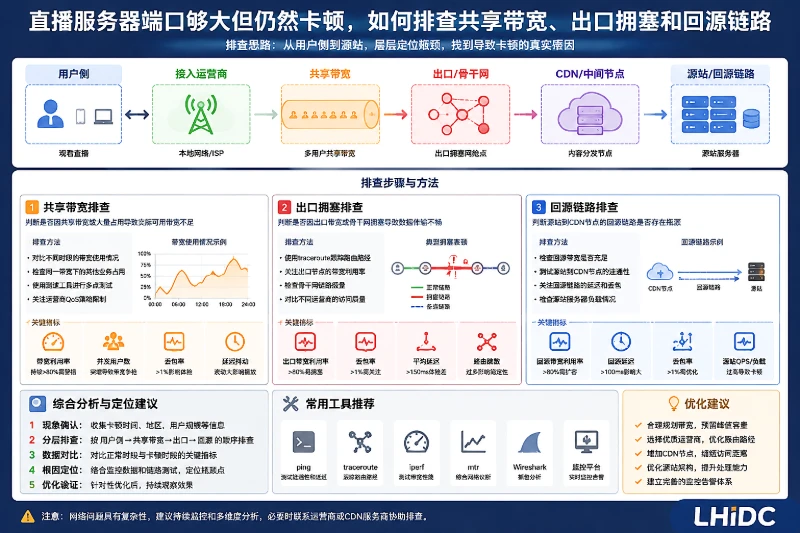
端口显示很大,直播仍然卡顿时先限定故障范围
直播故障现场经常会出现一个反常现象:服务器面板显示 1Gbps、10Gbps 端口,CPU 和内存也没有明显打满,但观众端仍然出现转圈、音画不同步、HLS 分片加载慢、FLV 播放断续。此时不能直接判断“服务器性能不够”,也不能把“端口速率够大”等同于“可用带宽够大”。
更稳妥的排查顺序是:先确认直播服务器实际推流、回源、播放出口各自消耗了多少带宽;再检查本机网卡、TCP 重传、应用日志;随后判断是否存在共享带宽争用、机房出口拥塞或跨运营商链路波动;如果使用 CDN,还要单独检查 CDN 到源站的回源链路。线路状态会随时间、运营商、测试点变化,排查时应以同一时间段的多点证据为准,避免凭单次测速下结论。
先分清端口速率、保障带宽和实际吞吐
直播卡顿排查中,最容易误判的是“端口”和“带宽”的关系。端口速率只是网络接口能够协商或限制的最高速率,不代表业务可以持续使用这么多带宽。
| 名称 | 含义 | 对直播业务的影响 |
|---|---|---|
| 端口速率 | 网卡或虚拟端口的链路上限,例如 1Gbps、10Gbps | 只说明理论出口上限,不代表可长期跑满 |
| 保障带宽 | 服务商承诺或套餐包含的可持续带宽能力 | 直播稳定性更应参考这一项 |
| 共享带宽 | 多台服务器或多个用户共用一个带宽池 | 低峰可能跑得高,高峰可能受其他业务影响 |
| 实际吞吐 | 观众或 CDN 节点实际收到的数据速率 | 受丢包、重传、路由、出口、客户端运营商影响 |
一个简单计算可以帮助判断方向:如果直播码率是 2Mbps,直接由源站向 500 名观众分发,理论出口已经接近:
2Mbps × 500 = 1000Mbps
实际还要考虑 TCP/IP 开销、HLS 分片突发、HTTPS 握手、播放器重连等因素。也就是说,即使服务器端口是 1Gbps,只要没有对应的保障带宽,或者观众峰值超过承载能力,卡顿就很正常。
如果使用 CDN,源站出口不一定等于观众总带宽,但回源瞬时流量仍可能很高。尤其是多个边缘节点同时回源、缓存命中率低、分片过短或直播间刚开播时,源站可能被回源请求打出突发峰值。
从本机开始确认:不是所有卡顿都来自外部线路
在怀疑共享带宽或出口拥塞之前,应先确认直播服务器自身没有明显瓶颈。以下命令以常见 Linux 环境为例,执行前请根据实际网卡名、系统版本和权限调整。
查看网卡协商速率和错误包
先确认当前网卡名称:
ip -br link
查看网卡统计信息,重点关注 RX/TX errors、dropped、overruns:
ip -s link show dev eth0
如果是物理服务器或支持读取链路信息的环境,可以查看协商速率:
ethtool eth0
需要注意,云服务器或虚拟化环境中,ethtool 看到的信息可能不完整,面板显示的端口速率也可能只是虚拟端口限制,仍需结合服务商带宽策略判断。
观察实时吞吐、重传和连接数
如果系统安装了 sysstat,可以用 sar 观察网卡流量和 TCP 状态:
sar -n DEV 1 10
sar -n TCP,ETCP 1 10
重点看:
txkB/s是否接近套餐带宽或限速阈值;- TCP 重传是否在卡顿时明显上升;
- 是否存在大量连接建立、关闭或重连;
- 卡顿发生时流量是持续高位,还是并未跑满但播放仍然慢。
查看当前连接概况:
ss -s
如果直播服务走 HTTP/HTTPS,可以粗略查看 80/443 端口连接数:
ss -tan state established '( sport = :80 or sport = :443 )' | wc -l
如果走 RTMP,常见端口是 1935,可根据实际服务端口调整:
ss -tan state established '( sport = :1935 )' | wc -l
这些命令不能直接证明线路拥塞,但可以帮助判断“服务器是否已经被连接数或出口流量压满”。
检查应用层:直播卡顿可能是分片、回源或服务进程造成的
直播服务器不只是网络设备。Nginx-RTMP、SRS、FFmpeg、媒体网关、转码服务、鉴权接口和源站 Web 服务都可能影响观看体验。
HLS/HTTP-FLV 重点看响应时间
如果 HLS 分片请求经常变慢,播放器会表现为缓冲不足。可以从访问日志中观察 .m3u8 和 .ts、.m4s 请求的状态码、响应时间和返回大小。
以 Nginx 为例,日志格式中建议包含以下字段:
log_format live '$remote_addr $time_local "$request" '
'$status $body_bytes_sent '
'$request_time "$http_user_agent"';
排查时重点看:
.m3u8是否频繁 404、403、5xx;.ts或.m4s分片是否出现响应时间突然变长;- 是否存在大量 499,说明客户端或 CDN 节点等待超时后主动断开;
- 同一时间段是否只有个别区域慢,还是所有来源都慢。
如果不方便改日志格式,至少要结合当前日志中已有字段判断状态码和请求量。修改 Nginx 配置前应先备份配置,并使用 nginx -t 检查语法后再重载。
nginx -t
用 curl 观察单个分片加载时间
选择一个实际播放中的 HLS 分片 URL,在不同网络测试点执行:
curl -o /dev/null -s -w \
"time_namelookup:%{time_namelookup}\ntime_connect:%{time_connect}\ntime_starttransfer:%{time_starttransfer}\ntime_total:%{time_total}\nspeed_download:%{speed_download}\n" \
"https://example.com/live/stream/segment.ts"
结果解释要谨慎:
time_connect高,可能是网络链路或 TCP 建连慢;time_starttransfer高,可能是源站生成分片、回源、磁盘或应用处理慢;speed_download低,可能是带宽不足、丢包重传或远端限速;- 单点结果不能代表全网,应至少从不同运营商、不同地区对比。
排查共享带宽:看高峰、看同池、看是否触发限速
共享带宽的典型特点是:低峰表现正常,高峰不稳定;服务器本机端口未必显示跑满,但到部分方向的实际吞吐下降。排查时不要只盯着服务器内的 txkB/s,还要看服务商控制台带宽图、套餐说明和峰值策略。
可以按以下顺序确认:
- 核对套餐中写的是“端口速率”“共享带宽”还是“独享/保障带宽”。
- 对比卡顿时间与带宽图峰值,确认是否接近计费带宽或限速阈值。
- 观察卡顿是否集中在晚高峰、活动峰值或同机房业务高峰。
- 从多个测试点下载同一个大文件或直播分片,比较不同线路表现。
- 向服务商提交同一时间段的服务器 IP、目标测试点、日志时间、MTR 结果和带宽图截图,请求核查共享带宽池或上联出口状态。
如果服务器带宽套餐本身只有 100M 保障,而业务峰值按码率和并发计算已经超过 100M,那么无论端口显示多大,直接扩端口都不一定解决问题,应该升级保障带宽、接入 CDN,或拆分源站和分发层。
判断出口拥塞:不要用单次丢包直接定性
出口拥塞通常表现为:本机资源正常,应用响应正常,但到某些运营商或区域的吞吐下降、延迟抖动增大、TCP 重传上升。它可能发生在机房出口、上游运营商、跨网互联点或目标用户侧链路,不能简单归因于某一家运营商。
使用 MTR 做路径观察
从直播服务器到测试点执行:
mtr -rwzc 100 目标IP
如果测试点也有权限,应反向执行:
mtr -rwzc 100 直播服务器IP
看 MTR 时要注意几个边界:
- 中间跳丢包不一定代表真实丢包,部分路由器会限制 ICMP;
- 只有后续所有跳都持续丢包,才更有参考价值;
- 正向和反向路径可能不同,只看单向不够;
- MTR 反映的是测试时刻路径状态,不能代表全天稳定性。
使用 iperf3 进行受控吞吐测试
如果有可控的测试服务器,可以用 iperf3 进行双向测试。服务端:
iperf3 -s
客户端测试正向:
iperf3 -c 测试服务器IP -t 30
测试反向:
iperf3 -c 测试服务器IP -R -t 30
iperf3 结果只对这两个测试点、该时间段、该路径有效。不要把某个公网测速站的结果直接当成机房出口结论,更不能用单点结果推断所有观众体验。
回源链路会把源站问题放大到所有观众端
很多直播架构是“推流端 → 源站直播服务器 → CDN 边缘节点 → 观众”。观众看到的卡顿,不一定发生在观众到 CDN 的最后一段,也可能是 CDN 回源慢、源站出流不稳定或推流入口抖动。
回源链路常见影响
- 推流入口丢包:源站收到的音视频本身不连续,所有观众都会受影响。
- 源站带宽不足:多个 CDN 节点同时回源时,源站出口被打满。
- 缓存命中率低:HLS 分片频繁回源,源站承受接近分发层的请求压力。
- 分片生成慢:转码或切片延迟导致 CDN 拿不到最新分片。
- 跨境或跨运营商回源:链路抖动会体现为边缘节点取源慢。
如何区分观众链路慢还是回源慢
可以从现象上初步分支:
| 现象 | 更可能的方向 | 下一步检查 |
|---|---|---|
| 所有地区同时卡顿 | 推流入口、源站、回源链路 | 查看推流日志、源站负载、CDN 回源状态 |
| 只有某个运营商卡顿 | 运营商路径或边缘节点问题 | 多点 MTR、CDN 节点日志、切换线路验证 |
| 开播初期卡顿,稳定后好转 | 缓存预热或回源突发 | 检查 CDN 缓存命中率和源站峰值 |
| 分片偶发 404 或延迟生成 | 切片、转码或存储问题 | 查看媒体服务日志和分片生成时间 |
| 源站带宽不高但观众慢 | 出口路径、TCP 重传或 CDN 节点问题 | 对比不同测试点下载分片耗时 |
如果 CDN 提供回源日志或状态码统计,应优先查看回源 5xx、回源超时、回源耗时、缓存命中率。没有这些数据时,可以在源站访问日志中按 CDN 节点 IP 或回源 User-Agent 过滤,观察请求量和响应时间。
根据排查结果选择处理方式
故障排查的价值不只是找到“哪里慢”,还要避免用错误手段扩容。
结果一:实际出口接近保障带宽
如果服务器 txkB/s 长时间接近套餐保障带宽,且日志中出现分片响应变慢、客户端重连增加,优先处理带宽容量:
- 升级保障带宽,而不是只升级端口速率;
- 使用 CDN 分发,避免源站直接承载大规模观众;
- 按码率、并发和峰值系数重新估算带宽;
- 将推流入口、转码、播放源站拆分,避免互相抢出口。
结果二:端口未跑满但 TCP 重传和抖动明显
这种情况更像链路质量问题或出口拥塞,需要保留证据后与服务商或线路提供方协同排查:
- 保留卡顿时间段的
sar -n TCP,ETCP输出; - 提供多点 MTR,最好包含正向和反向;
- 提供受影响运营商、地区、用户 IP 段样本;
- 对比同时间段其他线路或 CDN 节点表现;
- 必要时切换 BGP、CN2、国际线路或更适合目标用户的节点。
这里要避免直接写成“某运营商拥塞”。更准确的说法是:在某时间段、从某测试点到某服务器路径上观察到延迟、丢包或吞吐异常,需要结合上游路由和出口监控确认。
结果三:源站正常,CDN 回源慢
如果源站本机负载和带宽不高,但 CDN 日志显示回源耗时高,应重点优化回源链路:
- 将源站放在更接近 CDN 回源节点的机房或线路;
- 调整 HLS 分片时长和缓存策略,减少频繁回源;
- 检查源站是否限制了 CDN 节点连接数;
- 确认 HTTPS 握手、证书、回源 Host、鉴权接口没有额外延迟;
- 对热门直播间做预热或提高边缘缓存命中率。
结果四:只有少数观众端异常
如果大部分测试点正常,只有个别地区或网络环境卡顿,源站扩容可能没有明显效果。此时应收集用户端运营商、地区、播放协议、播放器日志和访问的 CDN 节点,再判断是否需要调度优化、切换节点或增加多线路分发。
选购直播服务器时不要只问“端口多大”
直播服务器采购时,建议把以下问题写进配置核对表:
- 端口速率是多少,保障带宽是多少,是否共享;
- 是否存在峰值限速、95 计费或突发带宽策略;
- 目标观众主要在哪些地区和运营商;
- 是否需要跨境访问,是否依赖 CN2、BGP 或多线调度;
- 源站是直接分发,还是只承担 CDN 回源;
- 直播码率、预计并发、峰值活动规模是多少;
- 是否有回源日志、带宽图和线路异常协查支持。
以 LHIDC 的香港服务器配置为例,香港 AMD 高性能服务器采用 AMD EPYC 4585PX、64G DDR5-5600、960G NVMe SSD,带宽为 25M CN2 + 100M BGP;香港至强大内存服务器采用 Intel Xeon Gold 6138、128G 内存、2×960G U.2 SSD,带宽同样为 25M CN2 + 100M BGP。此类配置在计算、内存和存储上适合承载直播相关的源站接口、业务后台、数据库、转码辅助或中小规模回源业务,但如果用作高并发观众直连播放,仍必须按 25M CN2 + 100M BGP 的带宽边界计算,不应因为 CPU 或端口显示较高就忽略带宽容量。
修复后的验证步骤
处理完成后,不要只看“当前能播放”。建议按故障发生时的同等条件复测:
- 在原故障时间段或相近高峰时段复测。
- 使用相同码率、相同直播间、相同播放协议验证。
- 从至少两个不同运营商测试点访问直播流。
- 观察源站
sar -n DEV、sar -n TCP,ETCP是否仍有异常峰值和重传。 - 检查 Nginx、SRS 或媒体服务日志中 4xx、5xx、499、请求耗时是否下降。
- 如果使用 CDN,对比回源耗时、回源错误率和缓存命中率。
- 让真实用户或监控节点持续观察一到两个业务高峰周期。
直播卡顿的排查核心不是证明“端口够不够大”,而是确认从推流、源站、回源、出口到观众端的每一段是否具备稳定吞吐。只有把端口速率、共享带宽、出口拥塞和回源链路分开验证,扩容或换线才不会变成盲目操作。