
日本CN2服务器接Cloudflare CDN时,源站该保留多少带宽余量
接入 Cloudflare CDN 后,源站并不会承接全部用户流量,但回源、动态请求和批量操作仍会带来明显压力。本文面向运维与运营人员,说明日本CN2服务器应如何预留带宽、CPU、内存和磁盘资源,并列出回源瓶颈的常见告警信号。
先把目标定清楚:源站不是接全量用户流量
把 Cloudflare CDN 接在日本CN2服务器前面之后,用户访问峰值通常不会等比例压到源站上。源站真正要承受的,是缓存未命中、动态接口、登录态页面、上传下载、后台操作、批量刷新缓存,以及各种重试带来的回源流量。
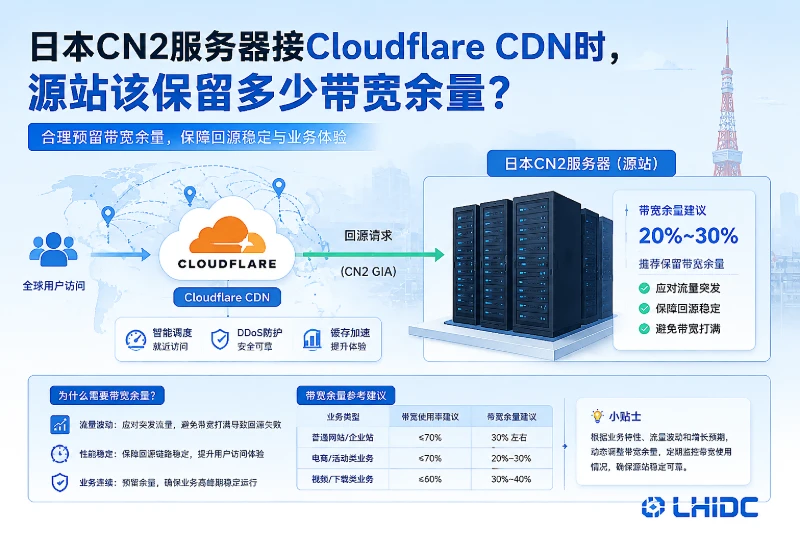
所以,源站带宽该留多少,不能只看“外部访问有多大”,而要看“有多少请求一定会回到源站”。如果你的站点以静态内容为主,且缓存策略稳定,源站带宽可以先按历史直连峰值的 30%~50% 做起点;如果是 CMS、企业站、带登录接口的平台,通常要按 50%~70% 预留;如果动态请求、下载、导出、频繁清缓存很多,余量就要更保守,很多时候要按接近峰值的 70%~100% 去看。
日本CN2线路的价值在于回源链路更稳、跨境抖动更可控,但它不会替你消化源站的 CPU、连接数、磁盘 I/O,也不会改变“缓存策略决定回源压力”这个基本事实。
环境检查:先拆流量,再定余量
先把请求分成三类
上线前先把流量拆开看,不然很容易把静态页的轻负载,误判成整个源站都很轻:
- 可缓存流量:图片、JS、CSS、版本固定的静态文件
- 必须回源流量:登录、支付、搜索、API、后台接口、个性化页面
- 例外流量:上传、导出、批量刷新、爬虫、预热、健康检查
如果源站的主要压力来自第二类和第三类,那么 Cloudflare 只能减少一部分带宽,并不能明显降低应用层压力。也就是说,回源流量与缓存策略高度相关,动态请求占比越高,源站留量就越不能按“静态站”来算。
带宽留量怎么起步
没有可靠的命中率数据时,不建议直接拍一个“固定节省比例”。更稳妥的做法,是按业务类型设一个起步余量,再留出突发空间。
| 业务类型 | 源站带宽起步建议 | 说明 |
|---|---|---|
| 静态为主的门户、博客、文档站 | 直连峰值的 30%~50% | 重点防回源突发和清缓存 |
| CMS、企业站、带登录功能的网站 | 直连峰值的 50%~70% | 动态页面和接口要单独算 |
| SaaS、API、下载、导出较多 | 直连峰值的 70%~100% | CDN 主要减轻边缘流量,源站仍要扛业务峰值 |
这里的“起步建议”不是固定答案,而是部署前的容量底线。真正上线时,还要再加一层 20% 左右的突发余量,避免缓存失效、批量刷新、节假日访问集中时把源站顶满。
带宽之外,还要预留这些资源
很多站点回源出问题,不是先死在带宽,而是先死在资源瓶颈上。
- CPU:回源高峰时,TLS、压缩、应用渲染、数据库查询都会吃 CPU。建议至少保留 30% 以上余量。
- 内存:缓存页、进程池、连接缓冲区都需要内存;一旦开始 swap,回源延迟会很快抬升。
- 磁盘 I/O:静态文件读取、日志写入、数据库读写都会受影响。磁盘利用率长期接近满载时,要优先扩容。
- 连接数:回源请求一多,keepalive、worker、文件描述符都可能先成为瓶颈。
如果是 Linux 源站,可以先看这些基础指标,确认是不是“带宽够了但机器已经快满了”:
uptime
free -h
ss -s
df -h
iostat -x 1 3
iostat 如果没有安装,先用现有监控替代,不要为了看一眼指标就直接改系统。
分阶段部署:先小范围上线,再扩到主流量
把 Cloudflare 接到日本CN2服务器前面,建议不要一次性把所有路径都放开。更稳的方式是先让静态占比高的目录、图片资源或单独子域名上线,再逐步扩到主站和动态接口。
第一步:先看静态流量的回源表现
先观察静态资源的回源压力是否明显下降,同时确认源站没有出现新的异常:
- 带宽峰值是否低于预留底线
- CPU 是否比直连时期更平稳
- 日志里有没有大量 404、403、5xx
- 页面首屏是否因为回源慢而变慢
如果静态资源都还在频繁回源,先别急着扩大范围,应该优先检查缓存策略是否过于保守、文件是否频繁更新、路径是否被误判为动态。
第二步:再放开动态接口和登录态页面
动态请求对源站的压力,通常不是体现在“总流量有多大”,而是体现在“峰值并发有多集中”。这类请求上线前要额外确认:
- 数据库连接池是否足够
- PHP-FPM、Java、Node.js、Go 服务的 worker 是否足够
- 接口超时设置是否合理
- 后端有没有依赖同一台机器上的本地磁盘或缓存
很多源站在接入 CDN 后,网页看起来已经被分流了,但 API 还是把 CPU 和数据库打满,问题根源不在 CDN,而在动态链路仍然是单点。
第三步:把批量任务和后台操作错峰
备份、日志归档、图片处理、导出任务、爬虫采集,这些任务最好不要和放量窗口重叠。原因很简单:Cloudflare 的回源流量本来就有突发性,如果后台任务再叠加上来,源站带宽和 I/O 很容易出现短时拥塞。
上线检查:出现这些信号,说明回源余量偏紧
下面这些信号,通常意味着源站该补余量了,不要等到用户投诉才处理。
- 带宽平均值不高,但峰值经常把链路顶满,随后出现丢包或抖动
- 页面 TTFB 变长,前端资源加载正常,但首屏明显慢
- Nginx/Apache 日志中 502、504 增多,或出现大量上游超时
- 499 增加,说明客户端等不住了,常见于源站响应慢
- CPU 长时间偏高,尤其是
sys、user占比上升明显 ss -s里 ESTAB、TIME_WAIT 持续堆积,连接池压力变大iostat里磁盘await升高、util逼近满载- 数据库慢查询增加,页面缓存失效后恢复速度明显变慢
如果你看到的是“流量不算大,但机器已经发热、日志告警、接口超时”,大概率不是 Cloudflare 没起作用,而是源站预留太紧,回源的连接、CPU 或磁盘先顶住了。
回滚条件:别等到源站被打满
上线后如果出现下面任意一种情况,就应该考虑先回滚到更保守的状态:
- 回源带宽连续一段时间逼近预留上限
- CPU、内存或磁盘 I/O 出现持续告警
- 5xx、超时、499 明显上升
- 数据库或应用线程池开始排队
- 业务高峰期的响应时间比直连时期更差
回滚不一定意味着全部撤掉 CDN,通常先恢复原来的稳定访问路径,暂停进一步放量,把静态和动态重新拆开,再重新统计源站直连峰值。只有拿到新的峰值和回源曲线,下一轮容量规划才有依据。