
日本CN2服务器部署API接口时,如何评估并发与带宽是否够用
部署API到日本CN2服务器时,不应只看带宽,而要结合峰值QPS、平均响应时间、请求体大小、数据库与缓存压力一起判断并发能力。文章给出API场景的资源评估项、够用标准和扩容触发条件,适合全栈开发工程师与API平台团队参考。
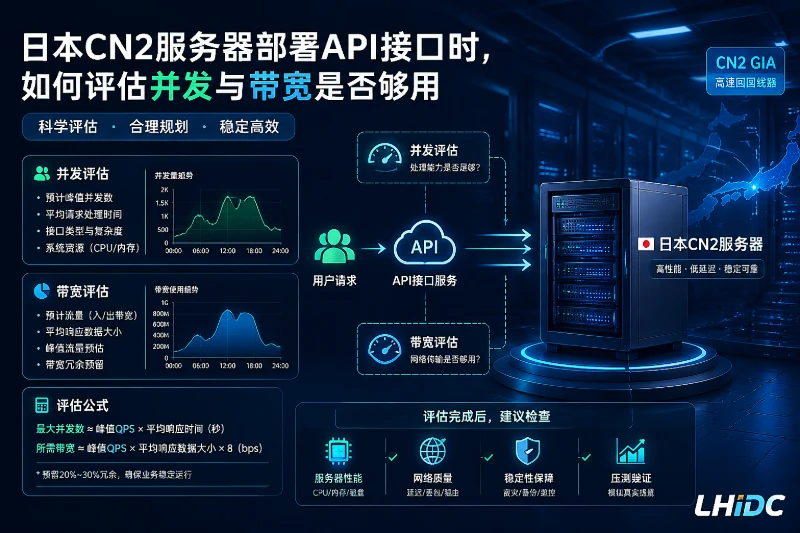
先把判断顺序摆正:并发不是先看带宽
API接口放到日本CN2服务器上,最容易走偏的一步,是先问“带宽够不够”,再问“并发能不能扛住”。实际顺序应该反过来:先算峰值请求会形成多少在途并发,再看这些请求会占用多长时间、消耗多少出站流量,最后才判断带宽是否真的是瓶颈。
如果接口主要是小体积 JSON 查询,真正先吃紧的往往是应用线程、数据库连接池、缓存命中率和第三方调用延迟;如果接口里有批量导出、文件上传、图片直传、长列表返回,带宽才更容易先到上限。也就是说,日本CN2服务器的线路价值主要体现在访问稳定和时延可控,但它并不能替代应用架构和数据库容量。
先排除几种不合适的选法
只按“线路好”判断并发能力
日本CN2线路能改善跨境访问体验,但“访问更稳”不等于“并发一定更高”。如果接口每次都要查库、做复杂鉴权、调用多个下游服务,线路改善只能缩短一部分网络等待,不能自动增加应用处理能力。
只按带宽买配置
带宽适合解决“传得出去”的问题,不适合解决“算不完”的问题。 例如同样是 API 网关,若返回体只有几 KB,升级带宽带来的收益可能很有限;若返回体动辄几十 KB,带宽就会很快变成硬约束。两种场景的采购重点完全不同。
把在线用户数当成并发
在线用户数只是外部量,并不等于服务器上的在途请求数。一个客户端可能长时间空闲,也可能连续发起多个请求;HTTP/2 还会复用连接。真正该看的是“峰值 QPS/RPS”和“平均响应时间”,而不是登录人数。
并发、响应时间和带宽到底是什么关系
对 API 接口服务器来说,并发更准确的含义是“同一时刻正在处理的请求数”。它和响应时间直接相关,关系可以用一个简单公式理解:
- 并发在途请求数 ≈ 峰值 QPS × 平均响应时间(秒)
- 带宽占用 ≈(请求体 + 响应体 + 头部与协议开销)× QPS × 8
这两个式子说明了一个关键事实:
- 响应时间越长,在同样 QPS 下,需要占用的并发槽位越多。
- 单次响应越大,在同样 QPS 下,占用的带宽越多。
举个示意例子: 如果峰值是 300 QPS,平均响应时间 250ms,那么在途并发大约是 75;如果平均响应时间变成 1 秒,在途并发就会升到 300。 如果平均响应体是 20KB,300 QPS 的单向出站流量大约是 6MB/s,折算接近 48Mbps;再加上请求体、协议开销、重试和峰值抖动,实际规划时就不能只按“48Mbps”卡死。
这里还有两个容易被忽略的点:
- 平均值不够,P95/P99 更重要。API 的排队和超时,通常先从尾延迟开始恶化。
- 压缩能降低带宽,但会增加 CPU。很多时候不是“带宽省了就一定更好”,而是把瓶颈从网络转移到了计算。
API场景要评估哪些资源
判断日本CN2服务器是否够用,不能只看一个带宽数字。更稳妥的做法,是把 API 场景拆成下面几项一起看。
| 评估项 | 重点看什么 | 常见误判 |
|---|---|---|
| 峰值 QPS/RPS | 真实峰值、突发峰值、活动期峰值 | 只看平均流量,忽略高峰 |
| 平均响应时间、P95、P99 | 请求是否排队、尾延迟是否抖动 | 只看平均响应时间 |
| 请求体/响应体大小 | 单次请求到底传多少字节 | 以为 QPS 高就一定先打满带宽 |
| CPU | 序列化、鉴权、加密、压缩是否吃满核心 | 带宽没满就以为服务器还有余量 |
| 内存 | 连接缓存、对象堆积、GC 压力 | 忽略长连接和大对象占用 |
| 数据库与缓存 | 连接池、慢查询、锁等待、缓存命中率 | 只把压力算在 API 进程上 |
| 出站/入站带宽 | 是否长期接近上限,是否有突发尖峰 | 只看网卡峰值,不看持续占用 |
| 连接数/文件描述符 | 长连接、HTTP/2、Keep-Alive 是否堆积 | 把连接数等同于并发处理能力 |
如果 API 是标准查询类接口,最先要看的是响应时间、数据库和缓存;如果 API 包含下载、导出、批量回传,带宽和连接数的重要性会明显上升。若是混合部署,把数据库也放在同一台机器上,磁盘 I/O 和锁等待还会进一步影响并发判断。
日本CN2服务器部署API时,真正该关注的不是“线路名”,而是路径稳定性
日本CN2服务器的价值,通常体现在跨境访问的时延和稳定性上。对于面向东亚、尤其是需要跨境访问稳定性的 API 平台,这种线路优势会让请求的波动更小,尾延迟更容易控制。
但这里要分清两件事:
- 线路稳定,只能减少网络层的随机抖动。
- 并发能力,仍然取决于应用层、数据库层和中间件层。
换句话说,低延迟可以降低单个请求占用的时间,间接提高同样 QPS 下的可承载并发,但它不能弥补这些问题:
- 数据库慢查询多
- 连接池太小
- 下游服务超时频繁
- 大对象序列化或压缩开销高
- 日志和缓存写入把磁盘拖慢
所以,API 接口放在日本CN2服务器上时,判断重点不是“这条线路是不是够快”,而是“在稳定链路下,当前应用架构能不能把请求快速释放出去”。
什么时候可以判断“够用”
下面这些条件同时满足,通常就可以认为当前配置还能继续承载现有 API 业务:
- 峰值 QPS 仍低于服务设计上限,并且保留了至少 30% 的余量
- 平均响应时间稳定,P95/P99 没有持续上漂
- CPU 持续利用率没有长期贴近高位,且不会因为压缩、加密、序列化而频繁打满
- 内存没有明显吃紧,GC 或内存回收没有引发明显停顿
- 数据库连接池没有长期等待,慢查询数量可控
- 出站带宽在峰值时也没有长期接近上限
这里的“够用”不是指完全空闲,而是指高峰期仍有可控余量。对 API 来说,最怕的是日常看起来正常,一到活动、发布、批处理或外部依赖波动时,排队和超时一起上来。
什么时候该考虑扩容
扩容触发条件,最好按“先确认瓶颈,再决定扩哪一项”的顺序来判断。
该优先看带宽的情况
- 出站带宽在高峰期持续接近上限,且不是短暂尖峰
- 大量响应体、导出文件或批量数据回传占比明显
- 重试、重复请求、压缩开销一起把流量顶高
- 业务目标是缩短跨境访问时延,同时接口输出体积也很大
这类场景下,带宽扩容、拆分大文件流量、把静态内容移到对象存储或 CDN,往往比单纯堆 CPU 更直接。
该优先看应用和数据库的情况
- 带宽没有明显吃满,但 P95/P99 响应时间持续上升
- CPU、内存、连接池或数据库等待先到瓶颈
- 超时、重试、5xx 错误开始增多
- 接口本身是小包高频查询,网络流量并不大
这说明问题不在带宽,而在计算、存储或下游依赖。此时继续加带宽,改善通常有限。
该考虑整体升级的情况
- 高峰期多个指标同时逼近边界
- 业务增长还会继续,且后续还有活动、国际化或接口扩展计划
- 现有架构已经无法通过拆分、缓存优化或流量削峰再争取余量
这时候才适合评估更高配置的日本CN2服务器,或者把 API 网关、业务服务、数据库拆开部署,避免所有压力都落在同一台机器上。
下单前先核对这几项
如果是准备把 API 接口迁到日本CN2服务器,建议先把下面几项核实清楚:
- 峰值 QPS 和高峰持续时间
- 单次请求与响应的平均大小,尤其是响应体
- 目标响应时间,重点看 P95/P99
- 是否有导出、下载、上传、批处理等大流量接口
- 数据库和缓存是否同机,还是独立部署
- 是否存在第三方接口调用、鉴权、压缩、加密等额外开销
- 高峰期是否预留至少 30% 的余量
把这些数据拿齐,再去看带宽和配置,判断会更稳。 上线前最好先用真实峰值流量做一次分层验证:先看 API 服务本身能撑到多少并发,再看数据库、出站带宽和超时是否先触边;如果其中任何一项先到边界,就按那个瓶颈扩容,而不是先默认“加大带宽就能解决”。