
韩国cn2服务器远程SSH卡顿,如何用mtr和ss区分链路抖动与服务端拥塞
面向Linux运维人员,本文通过mtr、ss、top和iostat等命令,分步骤判断韩国cn2服务器SSH卡顿究竟是链路抖动还是服务端拥塞。并补充DNS反查、认证延迟的排查思路,帮助快速定位故障来源。
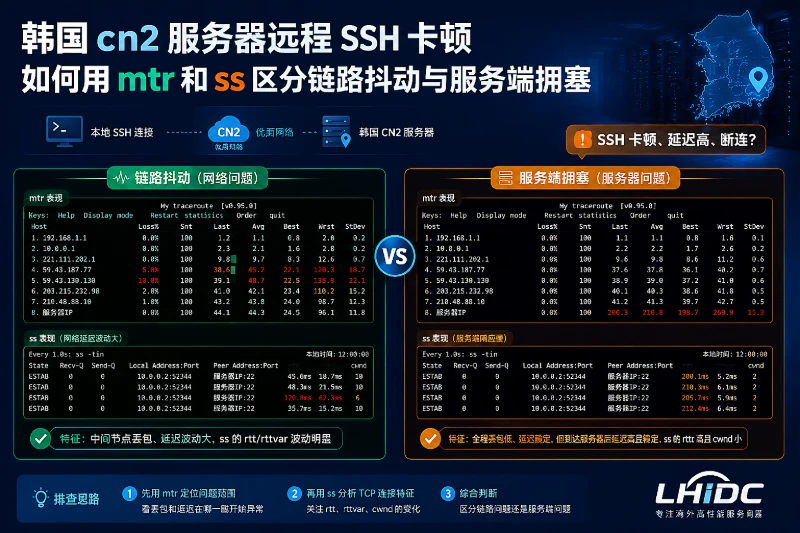
先把 SSH 卡顿分成两段
连到韩国 cn2 服务器时,SSH 交互突然变慢,最常见的表现不是断线,而是按键回显慢、回车后命令隔一拍才出来。这个现象不能只看 ping。单次 ping 只能说明某一刻到某个点的 ICMP 往返,不足以判断 SSH 这种 TCP 会话到底是链路抖动,还是服务器本身已经拥塞。
排查顺序要按层来:先复现卡顿,确认是“登录前慢”还是“登录后慢”;再用 mtr 看路径是否抖、是否持续丢包;接着用 ss 看这条 SSH 连接有没有重传、排队或异常状态;最后结合 top 和 iostat 判断是不是 CPU、磁盘或系统负载把 sshd 和 shell 卡住了。登录前慢,优先怀疑 DNS 反查或认证;登录后慢,优先看链路和主机资源。
用 mtr 看链路是否真的在抖
先准备工具。不同发行版包名略有差异,先按系统核对:
# Debian / Ubuntu
sudo apt update
sudo apt install -y mtr-tiny sysstat
# RHEL / CentOS / Rocky / AlmaLinux
sudo dnf install -y mtr sysstat
# 旧系统可用 yum
建议用报告模式跑久一点,不要只看几秒钟:
mtr -n -rw -c 100 -i 0.2 你的服务器IP
这里的含义很关键:
-n:不做 DNS 反查,避免名字解析把结果拖慢。-r:报告模式,适合保存和对比。-w:宽表输出,字段更完整。-c 100:发 100 个探测包,不要靠一两包下结论。-i 0.2:每 0.2 秒发一次,能更容易看到抖动。
看 mtr 时,重点不是“有没有某一跳掉点包”,而是最后一跳和整条路径是否一致:
Loss%:这一跳的探测丢包比例。中间某一跳丢包,不一定是真丢包,可能只是设备对 ICMP 限速。Avg/Best/Wrst/StDev:平均延迟、最好、最差和标准差。StDev大、Wrst经常冲高,说明链路抖动明显。- 最后一跳持续丢包,且前面多跳也同步抖动,才更像真实链路问题。
- 只有中间某跳丢包,但后面的跳数和最终目的地正常,通常先别归因到线路。
如果怀疑 ICMP 被限速,或者想更贴近 SSH 的 TCP 行为,可以再补跑一次 TCP 模式:
sudo mtr -n -T -P 22 -rw -c 100 -i 0.2 你的服务器IP
这一步不是必须,但在排查韩国 cn2 服务器这类跨境链路时很有价值。若 TCP 模式也显示最后一跳抖动明显,链路问题的可信度会更高。
用 ss 看连接状态和重传
mtr 只能说明路径大致稳不稳,ss 才能看到这条 SSH 连接在本机上的真实状态。服务器上看入站连接,客户端上看出站连接,方向不要搞反:
# 服务器侧,关注进入 22 端口的会话
ss -tnpi state established '( sport = :22 )'
# 客户端侧,关注连向 22 端口的会话
ss -tnpi state established '( dport = :22 )'
如果只想快速扫一眼,也可以看端口上的整体情况:
ss -tnp '( sport = :22 )'
重点看这几个字段:
State:正常交互会话通常是ESTAB。Recv-Q:到达本机但还没被进程读走的数据。Send-Q:已经发出但还没被确认,或者暂时发不出去的数据。retrans、rtt、rto:TCP 重传、往返时延和重传超时,ss -i会给出更细的信息。
判断时不要只盯着一个值:
ESTAB正常,但retrans持续增长、rtt和rto波动大,更偏向链路不稳。Recv-Q或Send-Q长时间不归零,且伴随多个 SSH 会话都变慢,更像主机侧处理不过来。- 如果看到很多
SYN-RECV、SYN-SENT,问题可能不在交互阶段,而在新连接建立阶段。 Recv-Q长,并不自动等于网络坏了。它也可能是 sshd、shell、认证模块或者下游程序没有及时读数据。
下面这个对照表,通常能快速缩小范围:
| 观察点 | 更像链路抖动 | 更像服务端拥塞 |
|---|---|---|
mtr 最后一跳 |
延迟跳变、StDev 高、持续丢包 |
基本稳定 |
ss |
retrans 增长,rtt 波动大 |
Recv-Q/Send-Q 堆积,连接状态异常增多 |
top / iostat |
资源正常 | CPU、wa、磁盘等待高 |
结合 top 和 iostat 找主机拥塞点
如果 mtr 看起来稳定,ss 也没有明显重传,但 SSH 还是卡,就要把注意力转到服务器本身。先看 CPU 和负载:
top -c
重点看:
load average是否持续偏高。us、sy是否长期很高。wa是否上升,wa高常意味着磁盘或存储等待。sshd、登录 shell、或刚进入后执行的程序是否占用异常。
再看磁盘和 IO 等待:
iostat -xz 1 5
这里重点看:
await:IO 等待时间是否偏高。%util:磁盘是否接近打满。r/s、w/s:读写是否突然增多。
常见场景有几种:
- 登录后第一条命令慢,可能是家目录在慢盘、NFS、网络挂载上,或者 shell 初始化脚本太重。
- 输入密码后才卡一下,可能是 PAM、LDAP、MFA、GSSAPI 或反查在拖慢认证。
- 多个会话同时卡,且
top显示 CPU 或wa飙高,服务端拥塞的可能性更大。
排除 DNS 反查和认证延迟
如果卡顿出现在“刚连接、还没进 shell”的阶段,先别急着怀疑链路。OpenSSH 服务器的 DNS 反查和认证流程,确实会把登录拖慢。先确认当前配置有没有启用反查:
sudo sshd -T | grep -i usedns
再看 SSH 认证相关日志。不同发行版路径不一样:
# systemd 日志,服务名按实际环境选择 sshd 或 ssh
sudo journalctl -u sshd -f
sudo journalctl -u ssh -f
# 传统日志路径
sudo tail -f /var/log/auth.log
sudo tail -f /var/log/secure
如果确认是反查拖慢,可以先在测试窗口里把 UseDNS 关掉,再验证是否改善。改动前先备份配置,并先检查语法:
sudo sshd -t
sudo systemctl reload sshd || sudo systemctl reload ssh
有些环境里,认证慢并不是 ss 或 mtr 的问题,而是:
- 反向 DNS 解析超时
- GSSAPI 认证等待
- PAM 接 LDAP / AD 超时
- 登录脚本访问了慢资源
这类问题往往表现为“连上去很久才出现密码提示”或“输完密码后迟迟不进 shell”,和真正的链路抖动不是一回事。
修复后怎么验证
处理完之后,不要只连一次就结束。按同样的路径复核一遍:
- 再跑一次
mtr -n -rw -c 100 -i 0.2 服务器IP,确认最后一跳没有持续丢包和明显抖动。 - 再跑一次
ss -tnpi state established '( sport = :22 )',看retrans是否还在增长,Recv-Q/Send-Q是否能保持平稳。 - 盯着
top -c和iostat -xz 1 5,确认 CPU、wa、磁盘等待回到正常范围。 - 重新开一个 SSH 会话,连续输入几条短命令,观察回显是否稳定。
如果同一时段里,mtr 一直抖,而 ss 和资源监控都正常,优先把问题归到链路;如果 mtr 稳、ss 里重传和队列异常、top/iostat 也在忙,优先处理服务器负载。把故障发生时间、mtr 报告、ss -ti 输出和资源截图留好,后续无论是找线路方还是回看本机任务,都能少走很多弯路。