
服务器端口不通却无拒绝回应时先比对SYN重试与路由返回
面向IT运维工程师,文章以“端口超时无回应”为起点,基于SYN重试、RST与路由返回信号建立分层判断流程,先剥离外部网络路径,再定位服务监听与主机策略。通过对应的验证命令和分支处理建议,帮助快速确认故障原因并完成回归验证,避免误判与盲目重启。
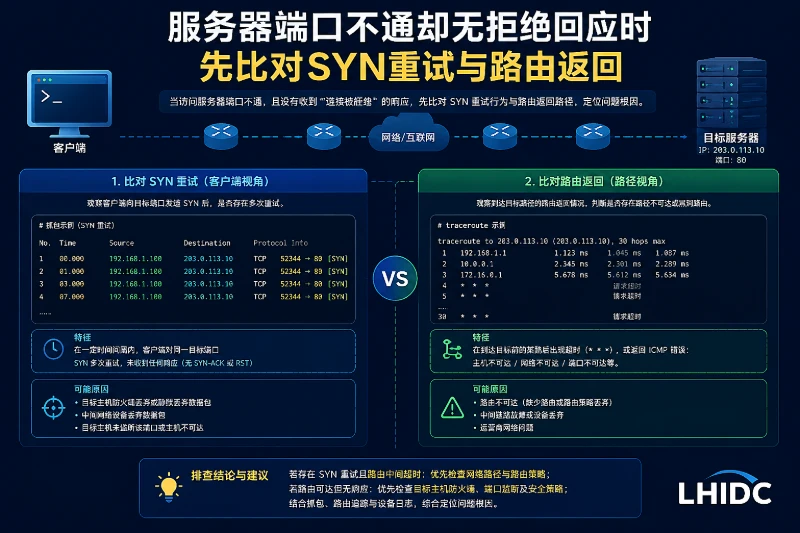
先确认故障范围,别被“无拒绝回应”误导
一个常见场景是:A 地区的监控显示某台服务器端口不通,监控脚本返回的是“连接超时”,抓到的只有客户端发出的 SYN 连续重试,没有 RST,但看起来像服务“彻底死掉”。
这种现象很容易在第一时间误判成应用故障,其实“无拒绝回应”只是说明它更像是网络层或策略层截断,并不一定代表服务未监听。要把判断闭环,先用一个条件:源端口、目的端口、目标 IP/域名、协议匹配无误,且你确认这是同一条链路(不是 DNS 指向了另外一个 IP)后,才进入“服务器端口不通”的正式排查。
本次处理建议按“先排除外部因素 → 定位服务端 → 修复 → 回归测试”推进。前两段内先把范围定清:
- 若
SYN重试之外还伴随路由返回,优先怀疑上游拒绝或路径策略; - 若无任何返回、纯超时,通常是路径静默丢包或本机防火墙丢包(
DROP); - 若直接回
RST,通常更接近端口未监听、绑定错误或本机显式拒绝。
先排除外部因素:先把网络和路由问题剥离掉
1. 对齐前置条件,避免先验错误
在看服务器端前,先确认这些“最容易遗漏但最容易导致误判”的点:
- 目标 IP 解析是否稳定:
ping解析出来的 IP 是否与运维文档一致。 - 测试端口是否一致:是业务端口(如 443)还是探测脚本使用了错误端口。
- 源端是否受限:出站是否被网段/出口策略限制,端口范围是否在 ACL 白名单之外。
- 服务器是否有 VIP/负载均衡转发:你测试的是 VIP,还是真机端口(经常在 SNAT 或端口漂移场景下误对齐)。
2. 外部可达性与路由返回先行判断
# Linux/macOS:确认链路层和逐跳是否正常
ping -c 3 <server_ip>
traceroute -n -q 1 <server_ip>
# Windows
Test-NetConnection -ComputerName <server_ip> -Port <port> -InformationLevel Detailed
tracert <server_ip>
# 抓“路由返回”,看是否有明确拒绝信号
sudo tcpdump -ni any -nn "icmp and host <server_ip>"
traceroute 连续卡在同一跳、tcpdump 收到 ICMP type 3(不可达类)或“通信被管理员禁止”等回复时,通常先处理上游策略/路由,不要急着改服务。
而只看到 SYN 重试,缺少任何 ICMP,要留意中间设备的静默丢包(例如ACL隐式DROP、某类IPS策略、异常ACL命中)或本机防火墙的 DROP。
用“连接状态 + 报文返回”做第一层主判据
TCP 连接状态为何重要
同一个“端口不通”下,客户端看起来都像超时,但状态分裂很关键:
SYN-SENT:客户端不断发送SYN,未看到对端响应,常见于网络丢包或无应答过滤。SYN-RECEIVED(在服务端侧可见):服务端已收到SYN并返回SYN-ACK,说明监听链路有反应,问题可能在中间返回路径/客户端返回路径。RST:目标系统或设备明确拒绝,通常意味着端口未监听、绑定失败、或防火墙/策略明确REJECT。Established:握手成功后可转到应用层,若这里失败,再看应用日志。
# Linux:观察目标端口相关的连接状态
ss -tan | grep ':<port>'
# 服务端抓包,确认 SYN 是否到达本机
sudo tcpdump -ni any -nn "tcp and dst host <client_ip> and tcp[tcpflags] & tcp-syn != 0"
结果分支对照(按现象走)
| 现象 | 典型报文/状态 | 先验结论 | 下一步 |
|---|---|---|---|
SYN 持续重试,客户端无回复,且无ICMP |
长时间 SYN-SENT |
先看路径策略或本机静默过滤 | 先比对外部 ACL/路由、再看本机防火墙计数器 |
客户端立即报 connection refused/收到 RST |
本机或边界设备显式 RST |
更接近端口未监听或显式拒绝 | 定位服务监听、绑定地址、防火墙 REJECT 规则 |
| 收到 ICMP unreachable(如 type3) | 有 路由返回 |
上游/边界设备在拒绝或不可达 | 检查路由表、上游 ACL、安全策略 |
| 部分源可达,部分源超时 | 某些源地址有 SYN-ACK 或失败 |
源地址维度的策略或归属网段问题 | 核对源 IP 白名单、NAT 后地址是否一致 |
注:ICMP 码的具体含义与厂商设备可能有差异,命令能确认存在“路由返回”,但归因仍需结合设备日志。
定位服务端:监听、绑定、策略三件事先做完
1. 服务是否真正监听且监听在正确地址
# Linux
ss -ltnp | grep ':<port>'
# Windows
Get-NetTCPConnection -LocalPort <port> -State Listen
若只看到 127.0.0.1:<port>,外部网络测试自然会超时。
若是容器/反向代理场景,确认服务端口与宿主映射是否一致(例如宿主监听端口与容器端口不一致)。
2. 检查主机防火墙是否在“静默丢包”
# 按实际环境选择其中一种
sudo iptables -S
sudo nft list ruleset
sudo ufw status verbose
# Windows 防火墙规则快照(便于回滚)
netsh advfirewall firewall show rule name=all | findstr /R /C:"<port>"
重点看两点:
- 是否存在
DROP但未LOG的规则,导致你看到的都是SYN重试; - 是否有按源网段/接口方向生效的细粒度拒绝规则。
如需临时放通,务必先备份当前策略,并限定源 IP 与端口,避免泛化放行:
# Linux 备份与最小放通示例(按需执行)
sudo iptables-save > /tmp/iptables.bak.$(date +%F_%H%M)
# 示例仅在明确故障窗口内使用,需后续立即回滚
sudo iptables -I INPUT -p tcp --dport <port> -s <client_ip>/32 -j ACCEPT
# Windows 临时规则(示例)
netsh advfirewall firewall add rule name="Tmp allow <port> debug" dir=in action=allow protocol=TCP localport=<port> remoteip=<client_ip>
3. 检查路由与回包路径是否在本机侧异常
ip route get <client_ip>
ip neigh show
如果服务端到客户端的源地址不在预期网段,可能出现“看起来服务可达但回包走错路由、被过滤”的问题。ip route get 能快速验证回复路径是否被劫持到异常网关。
按结果修复:不回头重启一锅端,而是逐分支处理
当你拿到分支后,修复动作通常是:
-
路由返回型(有ICMP):优先修策略,不动服务。 检查上游网关、边界防火墙、云网络ACL、黑洞路由;确认源/目的网段与端口在规则中都允许。若是多节点或跨网段,尽量从两侧(源和目的)同时抓包确认谁在第一时间返回不可达。
-
RST 型(明确拒绝):优先修服务端。 检查服务配置中的监听地址、端口重定向、进程状态,确认服务进程活跃且用户态监听正常。 若端口仅在本地监听,修改为预期外部地址或使用负载组件转发(例如反向代理)时确认
bind行为一致。 -
纯 SYN 重试(无返回):两侧都要核查。 外部层排除后,如果源到目的路径不稳定,多是本机防火墙/链路设备
DROP,或者服务端连接队列/内核参数导致异常丢弃。 可在高峰前观察SYN接收计数、连接建立速率,必要时结合应用层并发压力看是否出现端口监听背压;但在未确认队列瓶颈前不要直接调大系统参数,先恢复到可验证状态。
回归测试与风险提醒
修复后至少做一次“可复用”的回归:
- 同时从 23 个源点执行 2030 次连接探测,记录超时率。
- 观察一分钟窗口内
SYN重试与RST的比例是否下降。 - 用一次真实应用层请求验证端口成功后再看响应码,而不仅看 TCP 建连。
# 回归最小清单(示例)
for i in {1..30}; do nc -vz -w 2 <server_ip> <port>; done
# Linux 上观察端口相关连接状态是否回到可观测稳定态
ss -tan | grep ':<port>' | head
回滚提醒:临时规则、临时放通、临时变更都应有明确撤销命令和生效窗口。没有回滚点的“紧急修复”很容易把 服务器端口不通 从故障状态变成安全风险状态;在网络类故障处理里,验证和回滚是与修复同等重要的一步。