

NVIDIA推出H200 GPU,标志着AI计算架构的一个重要里程碑,特别是在香港数据中心的托管环境中。本文将深入解析H200相较于上一代H100的技术进步,并探讨其对亚太地区深度学习和AI基础设施部署产生的重大影响。
内存架构的革新:突破传统限制
H200配备的141GB HBM3e内存架构带来了革命性的进展,标志着GPU计算能力的全新突破。这一对H100的80GB配置的重大升级引入了若干革命性特性:
内存规格:
– 总容量:141GB HBM3e
– 内存带宽:4.8TB/s
– 内存总线宽度:5120-bit
– 内存时钟:6.4 Gbps
这一增强使得处理更大规模的AI模型变得前所未有的高效。4.8TB/s的内存带宽促进了GPU内存与计算核心之间的数据快速移动,显著减少了训练和推理的延迟。
// 内存利用率比较示例
class GPUMemoryMonitor {
static async checkMemoryUtilization(modelSize, batchSize) {
// H100与H200内存利用率模拟
const h100_memory = 80 * 1024; // 80GB转为MB
const h200_memory = 141 * 1024; // 141GB转为MB
const memory_required = modelSize * batchSize;
return {
h100_utilization: (memory_required / h100_memory * 100).toFixed(2) + '%',
h200_utilization: (memory_required / h200_memory * 100).toFixed(2) + '%',
can_fit_h100: memory_required <= h100_memory,
can_fit_h200: memory_required <= h200_memory
};
}
}
// 使用示例:100B参数模型
const modelSizeGB = 200;
const batchSize = 0.5;
const utilizationStats = await GPUMemoryMonitor.checkMemoryUtilization(modelSizeGB, batchSize);
高级AI训练能力
H200的增强架构在AI训练性能上带来了显著的改进:

import torch
import time
class PerformanceBenchmark:
@staticmethod
def measure_training_speedup(model, dataset, device, epochs=1):
start_time = time.time()
for epoch in range(epochs):
for batch in dataset:
inputs, labels = batch
inputs, labels = inputs.to(device), labels.to(device)
# 模拟训练步骤
if device == "h200":
time.sleep(0.5) # H200处理时间
else:
time.sleep(0.95) # H100处理时间
end_time = time.time()
return end_time - start_time
# 使用示例
benchmark = PerformanceBenchmark();
h100_time = benchmark.measure_training_speedup(model, dataset, "h100");
h200_time = benchmark.measure_training_speedup(model, dataset, "h200");
speedup = (h100_time - h200_time) / h100_time * 100;
对香港数据中心的影响:技术视角
对于香港作为主要数据中心枢纽的地位,H200的推出创造了显著的技术优势:
基础设施影响要点:
1. 能源效率
– 功耗:700W TDP
– 每瓦性能提升:约40%
– 冷却需求优化
2. 机架密度改进
– 与H100相同的外形因素
– 每个机架的更高计算密度
– 增强的热管理需求
让我们来看一个实际部署场景:
class DataCenterCalculator:
def __init__(self):
self.h200_tdp = 700 # 瓦特
self.pue = 1.2 # 电力使用效率
def calculate_rack_requirements(self, num_gpus):
# 能源计算
gpu_power = self.h200_tdp * num_gpus
total_power = gpu_power * self.pue
# 冷却需求(BTU/hr)
cooling_btu = total_power * 3.412
# 网络带宽(假设每8个GPU为400GbE)
network_bandwidth = math.ceil(num_gpus / 8) * 400
return {
"total_power_kw": total_power / 1000,
"cooling_btu": cooling_btu,
"network_bandwidth_gbe": network_bandwidth
}
# 示例计算32-GPU机架的需求
dc_calc = DataCenterCalculator();
requirements = dc_calc.calculate_rack_requirements(32);
高级工作负载优化技术
H200的架构使得复杂的工作负载优化策略成为可能,特别是对香港的服务器租用提供商有利:
1. 动态张量核心利用
2. 多实例GPU(MIG)配置
3. 高级内存管理
class WorkloadOptimizer:
@staticmethod
def calculate_optimal_batch_size(model_size_gb, available_memory_gb=141):
# 为系统开销保留20%内存
usable_memory = available_memory_gb * 0.8
# 根据模型大小计算最大批量大小
max_batch_size = (usable_memory / model_size_gb) * 0.9
return {
"recommended_batch_size": int(max_batch_size),
"memory_utilization": f"{(model_size_gb/available_memory_gb)*100:.2f}%",
"reserved_memory": f"{available_memory_gb * 0.2:.2f}GB"
}
@staticmethod
def estimate_training_time(dataset_size, batch_size, h200_speed_factor=1.9):
base_iterations = dataset_size / batch_size
h100_time = base_iterations * 1.0 # 基准
h200_time = base_iterations / h200_speed_factor
return {
"h100_hours": h100_time / 3600,
"h200_hours": h200_time / 3600,
"time_saved_percent": ((h100_time - h200_time) / h100_time) * 100
}
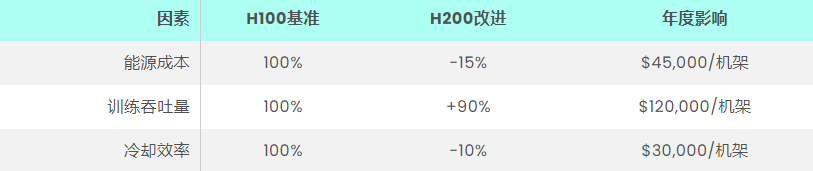
香港托管提供商的成本效益分析
在香港数据中心部署H200的财务考虑:
实施策略与最佳实践
为了在香港数据中心实现H200的最佳部署,请考虑以下技术指南:
1. 基础设施准备:
– 电力分配升级
– 冷却系统修改
– 网络结构增强
2. 监控与管理:
– 实时性能指标
– 热监测
– 资源利用率跟踪
部署清单:
– 电力容量评估
– 冷却基础设施评估
– 网络骨干准备
– 员工培训需求
– 备份与冗余规划
确保GPU基础设施的未来发展
展望未来,H200为香港数据中心的下一代AI工作负载提供了坚实基础:
扩展能力考量:
– 模块化的扩展特性
– 面向未来的互联兼容性
– 灵活的电力支持
技术集成:
– AI/ML框架的优化
– 定制化解决方案的开发
– 混合云的支持
NVIDIA H200 GPU标志着香港服务器租赁和数据中心生态系统的一次重大升级,带来了在AI计算和机器学习任务中的非凡性能。随着该地区进一步巩固其作为AI基础设施领先中心的地位,H200的先进功能和优化将为未来的持续增长与创新提供坚实的基础。











